Not too long ago I wrote a post on how we use search data to influence our information architecture decisions. In our quest to be even better, we’ve made a few modifications.
Originally we were only looking at keywords (each of the words you search for) and queries (your exact search, often a phrase). As a refresher, here’s the graph of our common queries at the time:
 Right away we can see some redundant queries. “staff directory” and “directory” are really people searching for the same thing. Similarly, “campus map” and “map” are both people looking for the campus map. Although this is useful information to know, as it lets us figure out what terminology to use, it’d be nice if we could condense things so we just saw what people were trying to find – these are the sites that should be more prominently linked.
Right away we can see some redundant queries. “staff directory” and “directory” are really people searching for the same thing. Similarly, “campus map” and “map” are both people looking for the campus map. Although this is useful information to know, as it lets us figure out what terminology to use, it’d be nice if we could condense things so we just saw what people were trying to find – these are the sites that should be more prominently linked.
So our first change was to condense the number of queries, by grouping related ones into their most common term. We didn’t do it for all of them – just the top 300 or so – but it was enough to represent the majority of our search traffic. Our second change was to increase the amount of data for better accuracy. We’re now looking at the top 500 keywords and queries every week, instead of just the top 100. After 12 weeks, that gives us 1523 different queries, and 921 different keywords.
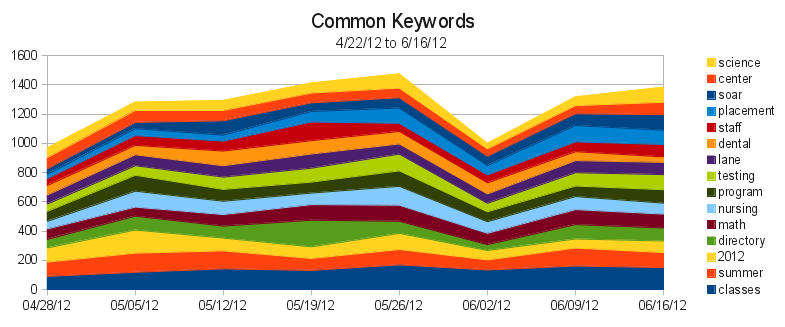
That much data means we needed a new, fancier way to get a big picture of it. Conveniently, as part of a different project, I’ve been learning to visualize data using d3.js *, and the thousands of points in our search data make a perfect starter project for me.
To really see the power of d3, you’ve got to see the graph in person. But here’s an image, in case you’re on an older browser (IE7 & 8 support is sketchy):

This particular type of graph is called a streamgraph. To read it, click on it to go to the website where it’s actually hosted, then mouse over a particular band. The width of that stream represents the proportion of traffic that searched that a particular query. The thickness of the river represents the total amount of traffic. Because a streamgraph sits around a central line, rather than a bottom line (like the one in the first image of this post), it’s easier to see changes in volatile data.
If you look at the graph on the webpage (and not here!), you’ll see a few dots below the graph. Mouse over them to see annotated events that we think might have contributed to sudden search bursts. Some of them, like the ExpressLane burst, are obvious. Others are just my guesses. And others are totally unidentified. If you have any ideas what might have caused one of those bursts, let me know in a comment, so I can have an even better understanding of how our site is used!
* I also cheated and used a project called Rickshaw, which provides an even gentler interface to d3 for time series data.