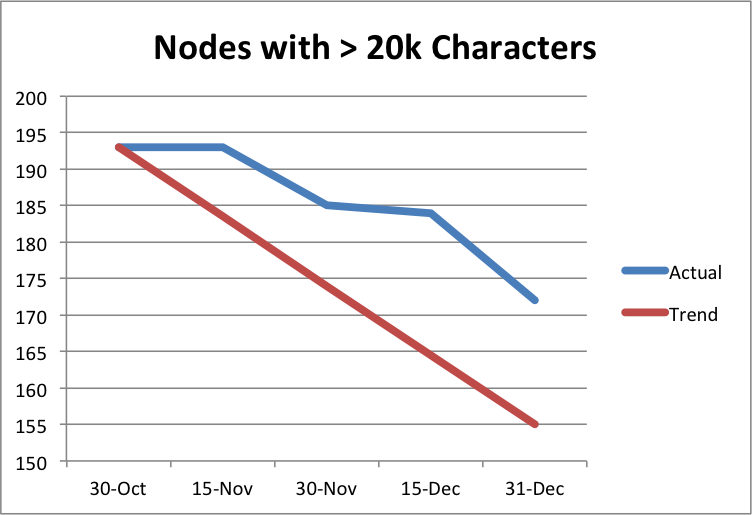
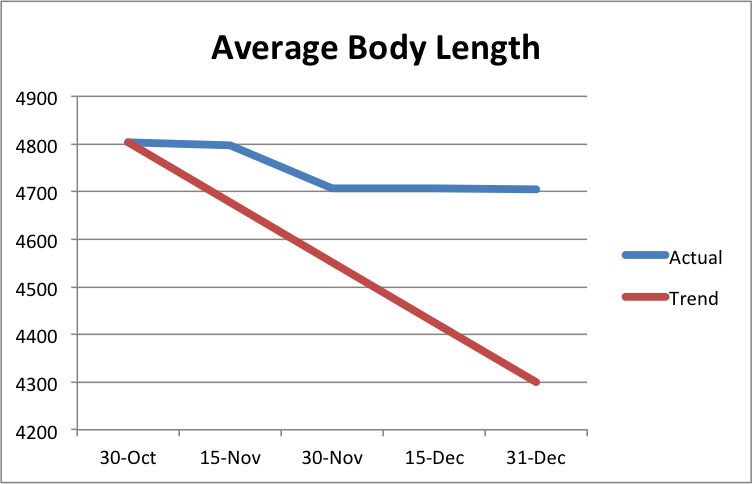
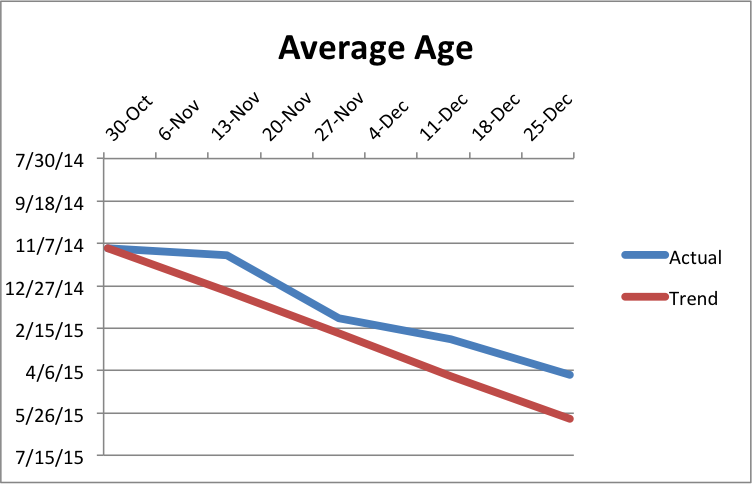
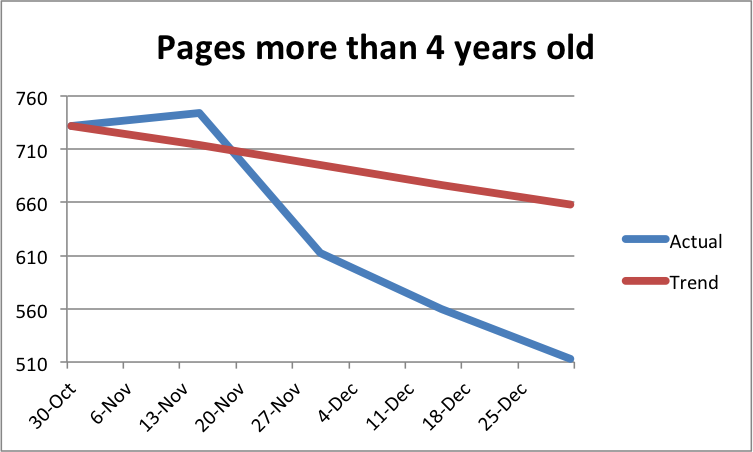
I’m taking a break from our accessibility posts this week to instead post on a couple bad practices I spotted across the website while trying to meet our website goals.
Many typewriters, especially less expensive ones, used the same amount of space for each letter – that way, the platen of the typewriter would advance the same amount no matter what character you typed. Your page would end up being monospaced – here’s an example on screen using a monospaced font:
Lane’s mission is to transform students’ lives through learning, but how do we know this is so? To know, we must develop clear learning outcomes and evaluate our curriculum and pedagogical practices regularly to ensure a quality learning environment. Assessment of student learning focuses on students’ attainment of knowledge and skills at the course and program or discipline level. This is accomplished by infusing the curriculum with general education learning outcomes intended to prepare students for success in the 21st century.
Because each character is the same width, it can be hard to distinguish sentences. So people taught to type on typewriters were often taught to include a second space after the period, like this:
Lane’s mission is to transform students’ lives through learning, but how do we know this is so? To know, we must develop clear learning outcomes and evaluate our curriculum and pedagogical practices regularly to ensure a quality learning environment. Assessment of student learning focuses on students’ attainment of knowledge and skills at the course and program or discipline level. This is accomplished by infusing the curriculum with general education learning outcomes intended to prepare students for success in the 21st century.
As computers and printers become commonplace, new fonts were available and proportional spaced fonts, which had always been used in professional printing, came back into use. Here’s our sample paragraph again in a proportional spaced font:
Lane’s mission is to transform students’ lives through learning, but how do we know this is so? To know, we must develop clear learning outcomes and evaluate our curriculum and pedagogical practices regularly to ensure a quality learning environment. Assessment of student learning focuses on students’ attainment of knowledge and skills at the course and program or discipline level. This is accomplished by infusing the curriculum with general education learning outcomes intended to prepare students for success in the 21st century.
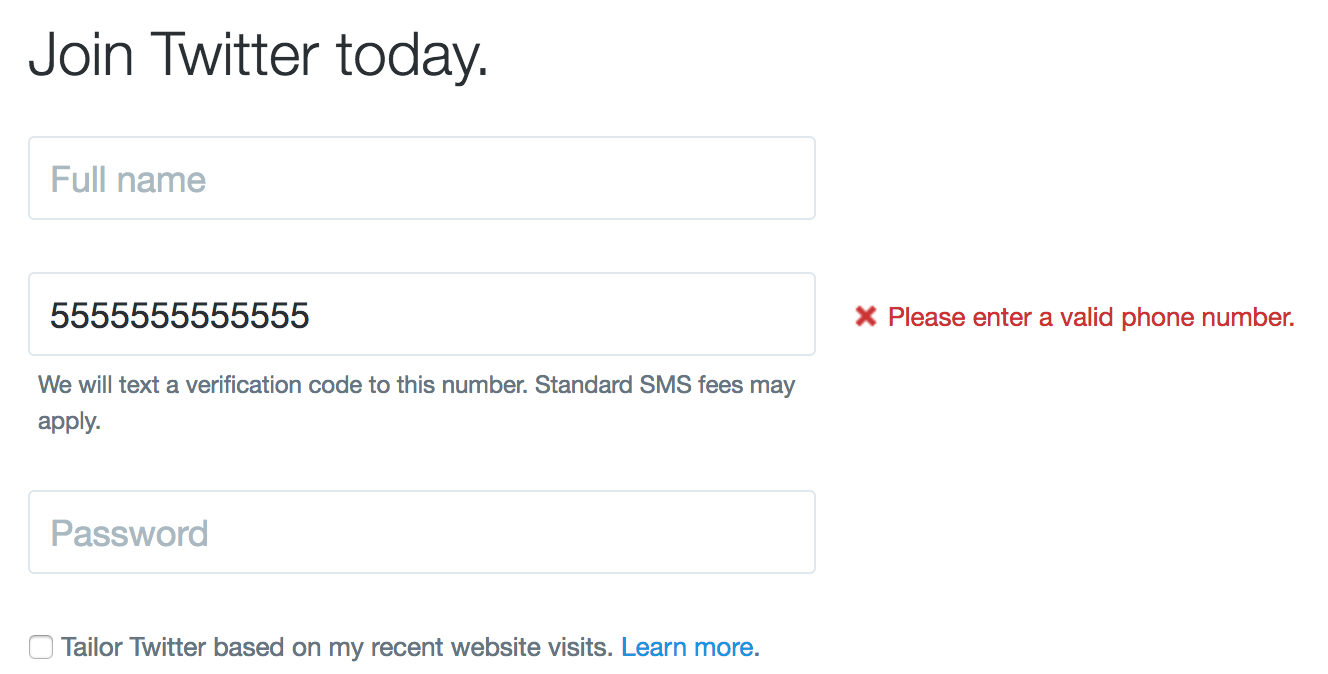
Every letter gets the appropriate amount of horizontal space. Narrow letters, like i, l, or I get much less space than wide letters, like W, M, or G. Characters like the comma or period are built with an appropriate amount of space after them already. So what happens if you were trained on a typewriter and have been typing double spaces your entire life? Right now, you get this:
Lane’s mission is to transform students’ lives through learning, but how do we know this is so? To know, we must develop clear learning outcomes and evaluate our curriculum and pedagogical practices regularly to ensure a quality learning environment. Assessment of student learning focuses on students’ attainment of knowledge and skills at the course and program or discipline level. This is accomplished by infusing the curriculum with general education learning outcomes intended to prepare students for success in the 21st century.
Let’s put aside that the font wasn’t designed to work with double spaces like that, leading to it looking like there’s holes in the text, and increasing the chance that our text will have rivers (in other words, it looks funny). Let’s instead talk about how HTML gets double spaces to work.
HTML wasn’t designed to support two spaces after a period, so browsers automatically collapse repeated spaces into just one. So to create to spaces after a period, as I did in some of the examples above, I had to insert a non-breaking space character. It’ll appear as a normal space when you’re viewing it, but if you were to look at the source of the page, you’d see – & in HTML means we’re about to start a character entity of some sort, the nbsp means non breaking space, and ; finishes the entity.
Non-breaking spaces act like invisible letters, and have some weird effects. They’re designed for places where the text shouldn’t break – that is, move onto two lines. So say we have a brand name, like ACME Products, that we don’t ever want to be on two lines. We’d put a non-breaking space between, like ACME Products, and then no matter how we resize the browser, we’ll always see those words together: ACME Products.
If you use them in regular text, you do weird things. If you have a space, followed by a non-breaking space, your non-breaking space might become the first letter in a line, and you’d have something like the second line of this paragraph. It just looks weird. If you’re not seeing it, here’s a picture (since you’ll only see it at certain widths):
 You might also have trouble centering things:
You might also have trouble centering things:
This line should be centered
This line is actually centered
I doubled the size of the text to make the problem more pronounced, but it’s true at any size. Since non-breaking spaces are invisible unless you know to view the source, they can be an endless source of frustration when you try to lay out your page.
There’s a place to use the non-breaking space, but almost everywhere it’s used on our website it’s used incorrectly. This week, we’ll be adding a filter to remove double spaces after periods when when the page is rendered. This is an imperfect solution, since the non-breaking spaces will still be present in the editor, and this won’t fix other problems, like the text centering problem above. But it will make our website look a little more uniform.
Horizontal Rules
The HR tag used to be strictly a presentation element – it was there so you could draw a horizontal line across your page. While HR’s are still usually rendered as a horizontal line, they now have a semantic meaning. From MDN: The HTML <hr> element represents a thematic break between paragraph-level elements (for example, a change of scene in a story, or a shift of topic with a section).
If your website uses HR’s to break paragraphs that have very different subjects, you’re in great shape. But if there’s another element that might indicate that break, then you shouldn’t use the HR. So, for example, if you have a series of paragraphs, each labeled by a header, don’t use an HR since the headers act as the break. Similarly, an HR should never be the first thing in a section (like pages that start with an HR), because there’s nothing to break at the start of a section. And you should never have more than one HR in a row.
We’ll be removing some HR’s from the site in the coming weeks where they’re not used properly. If you’d like some more info on HR’s, you can go into depth in the specification.