
The last standard we’ll explore in our series on understanding WCAG 2.0 is 4.1.1 Parsing. This standard is required for WCAG level A compliance, which is part of what Section 508 requires. Here’s the complete text:
4.1.1 Parsing: In content implemented using markup languages, elements have complete start and end tags, elements are nested according to their specifications, elements do not contain duplicate attributes, and any IDs are unique, except where the specifications allow these features. (Level A)
Web Browsers operate under a forgiveness by default principle. They’re very liberal in what sorts of input they accept, and they do their best to show you something. Here’s an example, taken straight from that link:
Hello!
If you inspect that line, you’ll find the color is specified as “sxbxxsreen”. “Sxbxxsreen” doesn’t exist as a color, either in the real world or within the browser. While most computer programs would either ignore “sxbxxsreen” or crash, browsers make a guess. Firefox converts the whole thing to a set of rgb hex values, using 0’s for invalid characters (look for Dak’s comments in that link for full explanation). Not every browser guesses the same way.
Web browsers also guess with malformed html:
<title>hello</title> <p>Hello! <body bgcolor="sxbxxsreen">
There’s no doctype, no html tag, no head tag, the p tag isn’t nested properly and doesn’t close, the specified background color doesn’t exist, and the body doesn’t close. But, amazingly, my web browser renders that page without complaint:
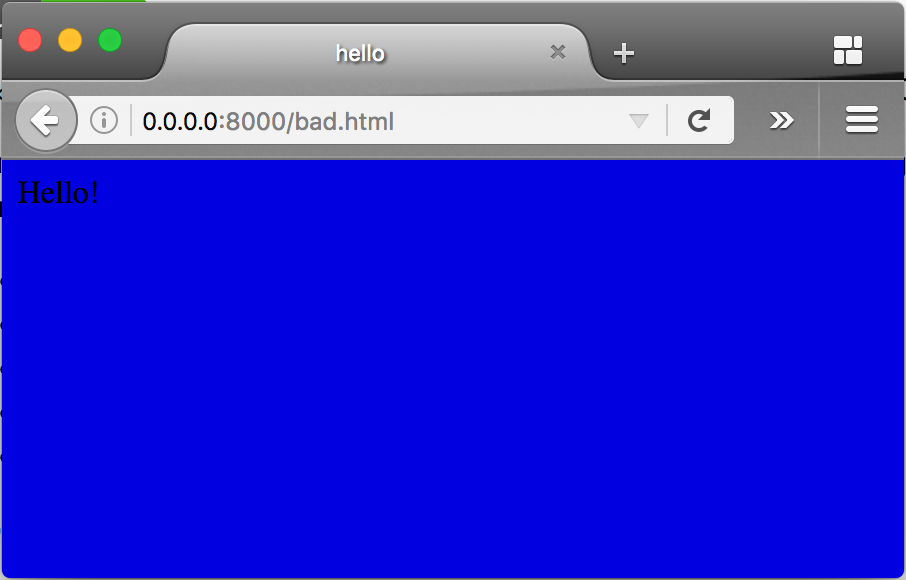 While this is generally a good thing (nobody really wants a browser to stop working because of a minor syntax error), it can become a problem if we depend on browsers to always guess correctly. A screen reader, which is a type of browser (though the WCAG specification refers to both browsers and screen readers as “user-agents“, I’m calling them browsers in these posts because user-agent has another meaning). And while most of us test our web pages to make sure they work in the most common browsers, none of us has every browser out there.
While this is generally a good thing (nobody really wants a browser to stop working because of a minor syntax error), it can become a problem if we depend on browsers to always guess correctly. A screen reader, which is a type of browser (though the WCAG specification refers to both browsers and screen readers as “user-agents“, I’m calling them browsers in these posts because user-agent has another meaning). And while most of us test our web pages to make sure they work in the most common browsers, none of us has every browser out there.
This standard requires four things: close open tags, nest tags correctly, don’t use duplicate attributes, and make ids unique. The easiest way to see if you meet those requirements is by validating your page. To do that, first make sure your doctype is correct, since that will tell the browser how to interpret the html. In older pages, you might see something like this at the very start of the source:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
But most new web pages use the HTML5 doctype:
<!doctype html>
which is the first and only doctype I can write from memory.
One your doctype is correct, you can use the W3C validator to check your document for errors. Here’s links for the legacy validator and the HTML5 validator.
If we validate the Lane home page, we’ll find many errors and warnings that don’t relate to the WCAG standard, and which we’ll have to interpret ourselves. For instance, there’s these:
- Attribute
xmlns:videonot allowed here. - Attribute
xmlns:productnot allowed here. - Attribute
xmlns:contentnot allowed here. - Attribute
xmlns:dcnot allowed here.
While technically these attributes aren’t supposed to be there (since they’re XML namespaces and not part of the HTML5 specification), none of them are duplicate attributes, so they’re allowed according to the WCAG 2.0 standard. This page also has a bunch of warnings. Some of them we can also ignore, but others are spot on:
- Consider avoiding viewport values that prevent users from resizing documents.
- The name attribute is obsolete. Consider putting an id attribute on the nearest container instead.
- Consider using the h1 element as a top-level heading only (all h1 elements are treated as top-level headings by many screen readers and other tools).
Without any doubt, I should fix those three warnings. But note what this validator didn’t find: missing tags, improper nesting, repeated attributes, or duplicate ids. In other words, this page meets this standard, even though there’s some work I should do, and even though it doesn’t technically validate.
If you’d like to know more about this standard, check out these examples and techniques.
Interested in more? Check out the listing of all the posts in this series.
I do find your work entertaining and right on. Thanks and your doing good work even if some of us do not catch the jokes… I do.
Glad someone appreciates them!